
La inteligencia artificial (IA) enfrenta un desafío crítico relacionado con la disponibilidad de datos. Según estudios recientes, para 2028 los conjuntos convencionales de datos textuales públicos alcanzarán un límite en términos de cantidad y calidad, lo que amenaza el desarrollo y escalado de modelos de lenguaje de gran tamaño (LLM, por sus siglas en inglés) como ChatGPT. Este problema no solo plantea preguntas sobre la sostenibilidad del avance en IA, sino también sobre la forma en que la tecnología se adapta a las restricciones actuales y futuras.
👉 nature La revolución de la IA se está quedando sin datos. ¿Qué pueden hacer los investigadores?
Por qué el lenguaje no es suficiente
Yann LeCun, uno de los pioneros en el campo de la IA, señala que los modelos entrenados exclusivamente con datos de texto no podrán alcanzar capacidades humanas completas. El futuro de la IA requerirá fuentes de datos más diversas, incluyendo experiencias sensoriales y datos del mundo real. Estos avances no solo exigen repensar los conjuntos de datos, sino también desarrollar modelos más eficientes y capaces de aprender con recursos limitados.
Los principales problemas en la disponibilidad de datos
- Consumo masivo de datos
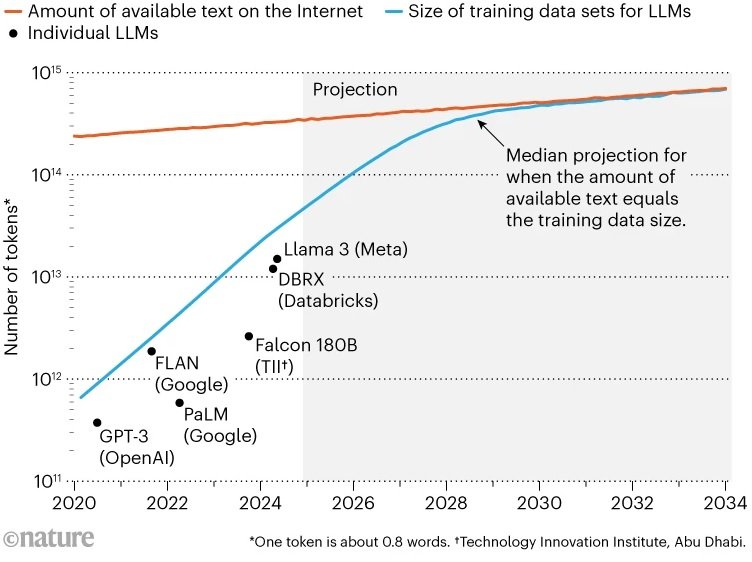
Desde 2020, el consumo de datos por parte de los LLM se ha multiplicado por 100, con modelos que procesan billones de palabras anualmente. Esta voracidad ha llevado al agotamiento de buena parte de los textos útiles disponibles en Internet. - Restricciones legales y técnicas
El acceso a datos en línea enfrenta barreras cada vez mayores. Editores y creadores de contenido han comenzado a bloquear rastreadores web y a emprender acciones legales, como las demandas de The New York Times contra OpenAI, limitando aún más el acceso a datos críticos para el entrenamiento de modelos. - Crecimiento lento del contenido en línea
La tasa de crecimiento del texto disponible en Internet es inferior al 10% anual, mientras que la demanda de datos por parte de los modelos de IA se duplica cada año. Este desbalance refuerza la urgencia de explorar soluciones alternativas.
Soluciones propuestas para mitigar la escasez de datos
Ante la crisis de datos, las empresas y los investigadores han comenzado a explorar diversas estrategias:
- Uso de datos no públicos y sintéticos
Algunas organizaciones están recurriendo a acuerdos privados para acceder a datos restringidos, así como a la generación de datos sintéticos y la colaboración con entrenadores humanos. Sin embargo, los datos sintéticos presentan riesgos significativos, como perpetuar errores a través de ciclos recursivos. - Fuentes especializadas
Áreas como la astronomía, la genómica o la salud ofrecen grandes volúmenes de datos especializados. Aunque útiles, su integración en modelos de lenguaje general enfrenta desafíos debido a la naturaleza específica y técnica de estos conjuntos de datos. - Relectura y optimización
Técnicas como la relectura de datos existentes pueden maximizar el rendimiento de los modelos sin necesidad de conjuntos adicionales. Además, mejoras en los algoritmos de aprendizaje pueden reducir la dependencia de cantidades masivas de datos.
Los términos clave para entender la crisis de datos
Para comprender mejor los retos y las soluciones en este ámbito, es fundamental familiarizarse con algunos términos clave:
- Tokens
Los tokens son las unidades mínimas de texto que los modelos procesan. Los LLM consumen actualmente billones de tokens anualmente, lo que refleja su enorme demanda de datos para mantener y mejorar su rendimiento. - Bienes comunes de datos
Estos son recursos públicos de datos textuales en línea, que están siendo rápidamente consumidos o restringidos debido a las limitaciones legales, técnicas y éticas. - Datos sintéticos
Contenido generado artificialmente para suplir la falta de datos reales. Aunque útiles, estos datos deben manejarse con cuidado para evitar sesgos y degradación en la calidad del modelo. - Modelos especializados
En lugar de depender de grandes volúmenes de datos generales, los modelos pequeños y enfocados en tareas específicas son una alternativa que reduce la necesidad de recursos extensivos.